|
 |
 |
|
|
|
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
FEATURE
|
Corpora
tips Next in a series of articles looking at ways in which words can be explored using corpus resources available on the Web.
I am writing an essay about my career plans, and I want to talk about goals. How does the word work? What sorts of sentences might I construct around it, with what collocates? The current range of EFL dictionaries aim to help, and are well-designed, sophisticated tools which specify grammatical patterns and collocates, and show the user a range of example sentences. Often that will be enough. But they are limited to a couple of column inches for a word like goal (in which they must cover all of its meanings) and sometimes they just do not cover the case the student (or teacher) is interested in. When that happens, where should they go next? One option is that they should go where the people who wrote the dictionary went themselves: to the corpus. The four ages of corpus lexicography Lexicographers face the issue of identifying how words behave every day, and, as they have realized for over a hundred years, the proper place to go to find out more is a corpus. A corpus is a set of texts as used as a resource for linguistic or literary study. In the first age of corpus lexicography, before the computer, corpus lexicography involved lots of paper and filing. An early and innovative exponent was James Murray, who compiled the Oxford English Dictionary with the help of over 20 million index cards, each with a citation for a word. Before writing an entry, he would find the index cards for a word and study the examples of usage they had on them. The second age dawned with the computer. In the 1970s,
Sue
Atkins and John Sinclair saw that the computer could revolutionise
corpus use, and initiated the COBUILD project to explore the idea. Rather
than starting from their own ideas about the word and what other dictionaries
had to say, lexicographers would base their analysis of a word purely
on the objective evidence, which the computer would furnish them with,
in the form of a fat wodge of computer printout (computers existed, yes,
but only in air-conditioned rooms tended by men in white coats; the era
of computers on desks was still far away). The computer printout would
be a Key-Word-In-Context (KWIC) concordance, in which there was
one line of text extracted for each occurrence of the word in the corpus
with the word of interest, e.g., goal, in the middle of the line.
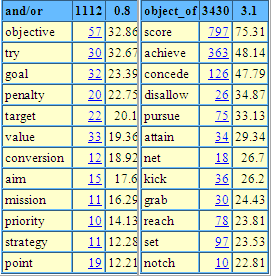
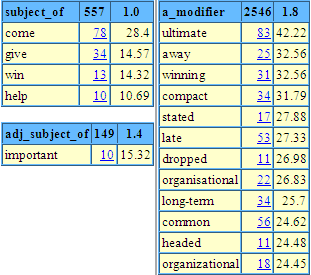
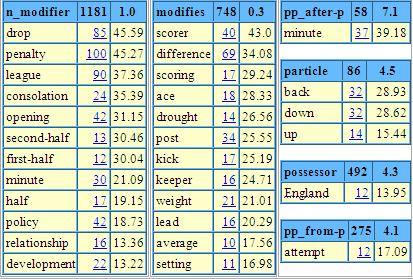
This is immediately useful. Just from the first few lines, we can see that we attain, lack and aspire to goals; that things are subjugated or subordinated to them; that there are eventual goals and goals ahead. This is rich information. Since the 1980s, KWIC concordances have transformed lexicography. All aspiring and innovative dictionary projects have gathered or borrowed a corpus. Computers have arrived on everyone's desk, ever faster and more powerful. Concordancing tools were developed which let the user call up and sort concordances instantly. And corpora have got bigger and bigger. The larger part of the COBUILD corpus was compiled using a corpus of 8 million words. That gave around 400 instances of goal, a lot to read, but does it cover all the patterns that the word occurs in? It is hard to say. A word like chug has just 28 occurrences in the 100-million word British National Corpus (BNC) so can only be expected to have something less than five in 8 million words. Bigger corpora are great because you have lots of evidence even for the less frequent words. In practice, the more data you look at the more patterns you find, so the discriminating lexicographer needs lots of data: they then have a range of patterns which may or may not be worthy of inclusion on the dictionary, and that is a choice for them to make. But how is the lexicographer going to find time to read all those corpus lines, and keep the patterns in their head for long enough to do a good job of distilling them? The bigger the corpus, the harder the problem. The answer brings us to the third age of corpus lexicography: summary statistics. The basic idea is simple. We get the computer to count all the words that occur frequently in the vicinity of the word of interest and present the results to the user. In the paper that inaugurated the third age (Church and Hanks 1989), the words found in the right context of save in a 40-million word corpus, were: forests, $1.2, lives, enormous, actually, jobs, money, life, dollars, costs, thousands, face, estimated and your. This isn't bad. We have been saved the labor of struggling through several thousand corpus instances, and have been pointed to saving forests, lives, jobs, dollars and face. The collocates have been sorted by Mutual Information, which does quite a good job of putting the linguistically interesting collocates at the top of the list. (In fact it tends to over-emphasize rare items at the expense of common ones, but we can apply an adjustment to address that problem.) Summary statistics have played a role in lexicography in the 1990s and 2000s, but rather less than might have been expected, given the time savings they offer. Why might that be? If we look at the table above, we can immediate see various irritants. We have both live and lives – why were they not rationalized into a single item? $1.2 and your are just junk, and even for the most efficient user, it wastes time to scan extra items that offer nothing. Enormous, annually, estimated and thousands are little better: there may be some linguistic significance to them occurring in the vicinity of save, but it will be objects of the verb that they modify rather than the verb itself, and the relation to save is indirect. With a little knowledge of grammar, a person can promptly organize a list like the above according to the relevant grammatical relations, weeding out the junk along the way. But – does it have to be a person? Another field that has been shifting apace is computational linguistics (also known as language technology, or language engineering, or natural (as opposed to computer) language processing). This field has, amongst its goals, automatic translation and question-answering, and, more humbly, the automatic discovery of grammatical structure. People in computational linguistics now can do a fair job of identifying grammatical relations (at least for much-studied languages like English). With computational linguistics techniques to hand, the fourth (and current) age dawns. We can now draw a 'sketch' – a one-page account of grammatical and collocational behavior – for a word as below. goal bnc freq = 10631
The word sketch is organized according to grammatical relations, with one list for collocates in each different relation. The relation names (on blue backgrounds) head each list. Collocates are listed according to the grammatical relation they occur in. In contrast to Figure 2, there is no junk: everything is there for an evident linguistic reason. The first number is the actual number of occurrences of the collocation (taken from the BNC; all data used here is from the BNC.) The second number is the salience statistic, used for sorting (a variant on Mutual Information). When working online, the user can click on the number and they are then shown the KWIC concordance for the collocation, so if they are unsure what a word is doing in the word sketch, they can promptly find out. Here, the items are lemmas (dictionary headwords) rather than word forms, so data for goal and goals are merged. A 'part of speech tagger' has been applied to work out, for example, where post is a verb ("post the letter") and where a noun ("goal post"). The word sketch as a whole is for the noun goal. Word sketches were first used for the Macmillan English Dictionary for Advanced Learners. They changed the way the lexicographers used the corpus. Rather than start with a KWIC concordance for the word, they went straight to the word sketch, as that summarized most of what they needed the concordances for. Goals occur, of course, in sport as well as life. The word sketch highlights the ambiguity. Scanning the 'object-of' list, if we score, concede, disallow, net or kick goals, we are talking sport; if we achieve, pursue, attain or reach them, life. England football fans will be glad to see England standing alone in the 'possessor' relation to goals! Will this help the student (or teacher)? Maybe. Earlier tools for corpus lexicography would not have been so useful, as it took more expertise to read the corpus lines and distill the linguistically useful facts; moreover heavy-duty computers were required so there was little practical possibility. Now the tools mean the output is more user-friendly, almost like a dictionary entry, and we have the web: heavy duty computers are still required, but they can hum away happily in cyberspace without the student needing to think about them. Word sketches are an appropriate tool only for advanced learners, or for students and teachers who want to delve deeper into linguistics and the English language; for them, it may well prove a direct route to what they want to know about a word. Word sketches can be explored at www.sketchengine.co.uk. |
||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||